
오늘도 진행중인 프로젝트의 코드를 작성하며 시간을 보냈다.
기존에 작성해둔 코드들을 QueryDsl을 이용해 최적화하는 시간을 가졌다. 생각보다 쉽지 않아서 시간이 좀 오래 걸렸다.
여기에 그 내용을 간단하게 적어본다.
1. QueryDsl을 이용한 최적화
먼저 나는 프로젝트에서 Course 부분에 대해서 최적화를 담당하였다. 주로 한 일은 N+1 문제가 발생하는 부분을 수정하는 것이었다.
먼저 N+1이 발생하는 부분은 다음과 같다.
코스 전체 조회: 전체 코스를 조회하는 쿼리(1회) + 코스를 개설한 셰프의 정보를 불러오는 쿼리(최대 N회) + 코스의 좋아요 개수를 조회하는 쿼리(N회)
내가 팔로우한 셰프의 코스 조회: 내가 팔로우한 셰프들을 불러오는 쿼리(1회) + 내가 팔로우한 셰프들이 개설한 코스를 조회하는 쿼리(1회) + 코스를 개설한 셰프의 정보를 불러오는 쿼리(최대 N회) + 코스의 좋아요 개수를 조회하는 쿼리(N회)
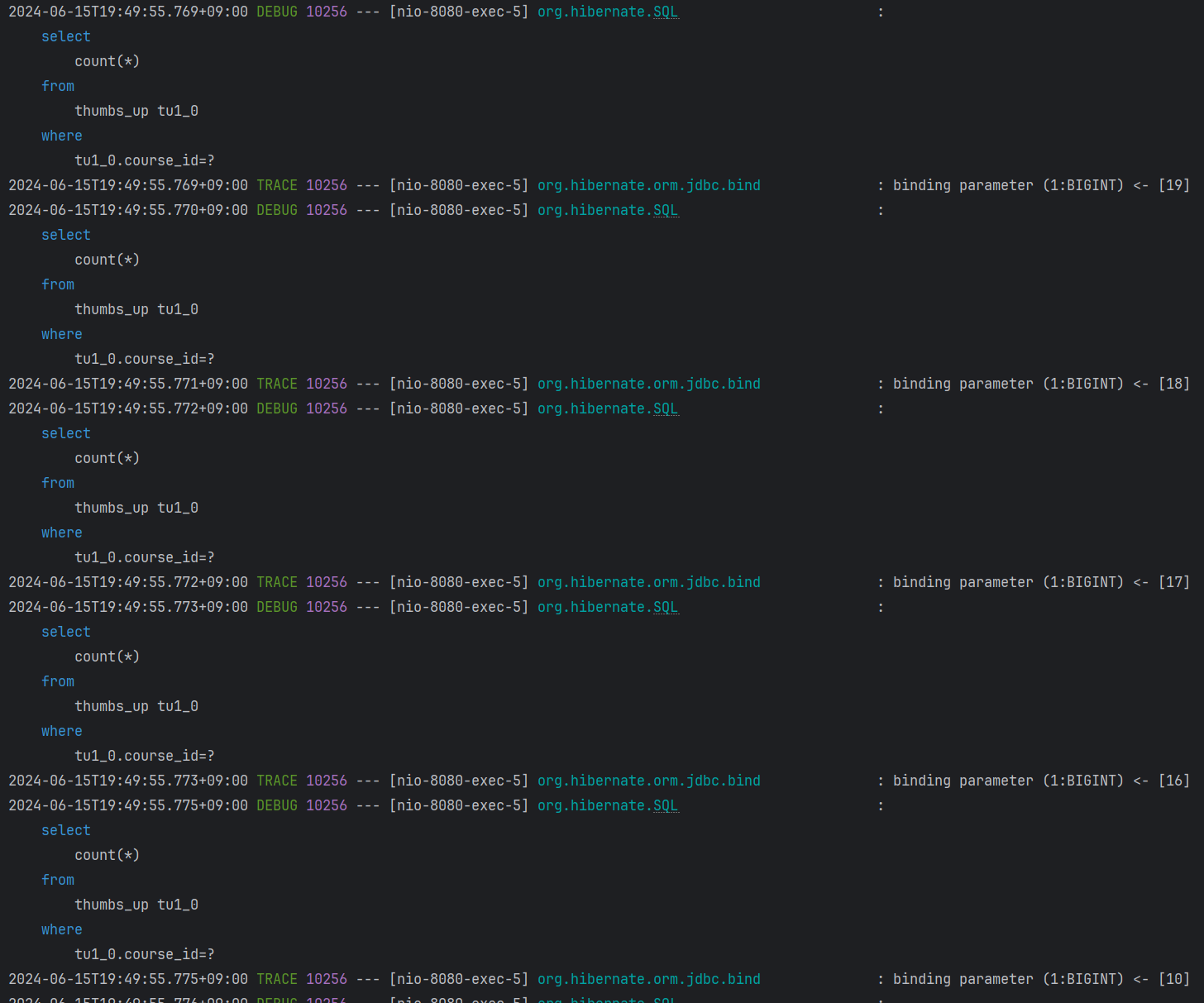
위와 같이 쿼리가 불필요하게 너무 많이 발생하는 문제가 있어서 쿼리의 개수를 줄여보기로 했다.
먼저 코스를 개설한 셰프의 정보를 불러오는 쿼리의 경우는 연관관계가 맺혀있었기 때문에 fetch join을 사용하여 매우 쉽게 해결이 가능했다.
연관관계 없이 좋아요 테이블에서 카운트를 세서 가져오려니 이 부분이 굉장히 힘들었다. 쿼리 하나로 모든 것을 해결해볼까도 생각했는데 생각보다 쉽지 않아서 쿼리는 두 번으로 나누었고, 나중에 결과물을 합치기로 하였다.
아래와 같이 전체 코스 조회하는 쿼리를 작성하였다. 두 개의 리스트가 Pair로 반환된다.
override fun searchOpenCourseListWithThumbsUpCount(): Pair<List<Course>, List<Long>> {
val openCourseListWithUser = queryFactory
.selectFrom(course)
.leftJoin(course.user, user).fetchJoin()
.where(course.status.eq(CourseStatus.OPEN))
.orderBy(course.createdAt.desc())
.fetch()
val count = queryFactory
.select(
course.id,
thumbsUp.course.id.count()
)
.from(course)
.leftJoin(thumbsUp).on(thumbsUp.course.id.eq(course.id))
.where(course.status.eq(CourseStatus.OPEN))
.groupBy(course.id)
.orderBy(course.createdAt.desc())
.fetch()
val countList = count.map { it.get(thumbsUp.course.id.count())!! }
return openCourseListWithUser to countList
}이후에 서비스에서 두 개의 리스트를 하나로 합쳐 DTO로 변환만 시켜주면 되었다.
fun getCourseList(): List<CourseResponse> {
val (openCourseListWithUser, countList) = courseRepository.searchOpenCourseListWithThumbsUpCount()
return openCourseListWithUser.zip(countList) { a, b -> CourseResponse.from(a, b) }
}
내가 구독한 셰프의 쿼리 조회도 위와 비슷하기 때문에 따로 코드를 여기에 올리지는 않을 생각이다. 내가 구독한 셰프의 목록을 따로 조회하지 않고 중첩 서브쿼리로 만들어서 처리했고, 그랬기 때문에 위와 비슷한 형태로 두 번의 쿼리로 모든 것을 끝낼 수 있었다.
위와 같이 작성 했더니 수많은 쿼리가 발생했던 부분들이 단 2 번의 쿼리로 모두 해결되었다.
전체 코스 조회를 예시로 들면 다음과 같다. 전체 코스 조회시 코스를 만든 셰프의 정보도 Fetch Join으로 불러오는 쿼리(1회) + 전체 코스에 대한 좋아요 개수를 조인으로 한번에 불러오는 쿼리(1회) 이렇게 총 2회의 쿼리가 발생한다.
물론 아쉬운 점은 최적화에 대해서 성능이 어떻게 얼마나 향상되었는지 확인해 볼 수 없었다는 점이다.
최적화를 하고 난 뒤에도 찜찜함이 남았는데 위와 같이 쿼리의 개수를 줄였다고 정말로 성능이 향상되었는지 확인할 수 없다는 점이다.
또한 서브 쿼리를 이용하여 쿼리의 개수를 줄이기 보다는 , 따로따로 조회한 뒤 합치는 것이 더 빠를 수도 있지 않을까 의심할 수 밖에 없었다.
성능최적화라고 하기는 했지만 사실 스웨거로 몇번 테스트해 본 것이 전부이기 때문에 수없이 발생하는 쿼리로 인한 성능저하를 경험해 본 적도 없고, 실제로 최적화가 되었는지 조차도 명백히 확인해보지도 못했다는 것이 아쉬운 점으로 남았다. 나중에 성능 측정 방법을 알게되면 꼭 실험을 통해서 눈으로 직접 확인해보고 싶다.
2. 오늘 배운 것
- QueryDsl에 익숙하지 않다보니 적용하는데 어려움이 꽤 있었다. 그래도 잘 마무리한 것 같아 다행이다.
- SQL 공부를 꾸준히 해왔던 것이 도움이 어느정도 된 것 같다. 그렇지만 아직 잘 모르는 부분이 많은 것 같아서 앞으로도 꾸준히 공부해야 겠다는 생각이 들었다.
'오늘 배운 것' 카테고리의 다른 글
| 24-06-17 알고리즘 문제 풀이 (0) | 2024.06.17 |
|---|---|
| 24-06-16 알고리즘 문제 풀이 (0) | 2024.06.16 |
| 24-06-14 AWS S3 저장소 이용해보기 (0) | 2024.06.14 |
| 24-06-13 JPA 복합키 매핑하기 (0) | 2024.06.13 |
| 24-06-12 알고리즘 문제 풀이 (0) | 2024.06.12 |